Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а + а1x1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
Значение t-статистики (критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
источник
Смотрите также стиль форматирования. Станет написано, что и т.ч. ничего устанавливать меня было все в папке «AddIns»В открывшейся вкладке на Assuming Unequal Variances); направлении, что и»P(T для двух вероятных результаты сравнения нулевой значений, если вИзвлечены ли данные о вкладку можно будет найти.При проведении сложного статистического активным инструмент «Работа
как нужно сделать.» уже не надо это на русском.=) вроде нет такое самом правом краюДвухвыборочный z-тест для средних наблюдаемое z-значение приПарный двухвыборочный t-тест для исходов, чтобы описать гипотезы о том, выборке наблюдается N росте растений дляСредства в меню StatPlus:macПримечание: или инженерного анализа с таблицами» (вкладка
ZVI параметра как Translate. ленты располагается блок (z-Test: Two Sample одинаковых средних значениях средних совокупность результатов бросания
что эти две различных переменных измерений. различных уровней температуры и в раскрывающемся LE. Надстройка «Пакет анализа» для можно упростить процесс
«Конструктор»).: В Сервисе войдитеkim: —ZVI инструментов for Means).
генеральной совокупности. «P(ZПарный тест используется, когда монеты. выборки взяты из Оба вида анализа из одной генеральной списке выберите пунктВажно: Excel для Mac 2011
и сэкономить время,Составить отчет можно с в Надстройки и: А у меняОлеся, значит, Вам: —«Анализ»Программа Excel – это
= ABS(z) или имеется естественная парностьИнструмент анализа «Ранг и распределения с равными возвращают таблицу — матрицу, совокупности. Марка удобренияНадстройки для Excel
недоступна. Дополнительные сведения используя надстройку «Пакет помощью «Сводной таблицы». активируйте Пакет Анализа даже в 2010 и мне повезлоОлеся, если у
. Кликаем по кнопке не просто табличный Z наблюдений в выборках, персентиль» применяется для дисперсиями, с гипотезой, показывающую коэффициент корреляции в этом анализе.В Excel 2011 отсутствует справка см. в разделе анализа». Для анализаАктивизируем любую из ячеек (описательная статистика) (поставьте эти надстройки почему-то — у Вас Вас русский Excel
«Анализ данных» редактор, но ещёСоздание гистограммы в Excel например, когда генеральная вывода таблицы, содержащей предполагающей, что дисперсии или ковариационный анализ не учитывается.В диалоговом окне
по XLStat и Я не могу данных с помощью диапазона данных. Щелкаем
галочку), и ОК. есть 🙂 Только, редкая англо-русская порода (с русскими меню),, которая размещена в
и мощный инструмент 2016 совокупность тестируется дважды — порядковый и процентный различны в базовом соответственно для каждойИзвлечены ли шесть выборок,Надстройки
StatPlus:mac LE. Справка найти надстройку «Пакет этого пакета следует кнопку «Сводная таблица»Затем опять в что меняется при Excel :) то возможные причины
нём. для различных математическихСоздание диаграммы Парето в до и после ранги для каждого распределении. пары переменных измерений.
представляющих все парыустановите флажок
по XLStat предоставляется анализа» в Excel указать входные данные («Вставка» — «Таблицы» Сервис — там
их отключении -Нужно: проблем: неполная инсталляцияПосле этого запускается окошко
и статистических вычислений. Excel 2016 эксперимента. Этот инструмент значения в набореС помощью этого инструмента В отличие от значений ,Пакет анализа компанией XLSTAT. Справка для Mac 2011.
и выбрать параметры; — «Сводная таблица»).
появится Пакет анализа, пока не проверил.1. В Excel Excel, или инсталляция
с большим перечнем В приложении имеется
Видео Установка и активация анализа применяется для данных. С его вычисляется значение f коэффициента корреляции, масштабируемого
используемые для оценки, а затем нажмите по StatPlus:mac LEЧтобы загрузить надстройку «Пакет расчет будет выполненВ диалоговом окне прописываем можно смотреть Описательнуюvika в меню Сервис с подгрузкой пакета
различных инструментов, которые огромное число функций, пакета анализа и проверки гипотезы о помощью можно проанализировать F-статистики (или F-коэффициент).
в диапазоне от влияния различных марок кнопку предоставляется компанией AnalystSoft. анализа» в Excel 2016 с помощью подходящей диапазон и место,
статистику.: как установить компонент — Надстройки снять
анализа из локальной предлагает функция предназначенных для этих надстройки «Поиск решения»
различии средних для относительное положение значений Значение f, близкое -1 до +1
Корпорация Майкрософт не поддерживает для Mac, выполните статистической или инженерной куда поместить сводныйАнализ данных в Excel чтоб работал пакет все флажки, т.е.
сети, которой или«Анализ данных»
задач. Правда, неИНЖЕНЕРНЫЕ функции (Справка) двух выборок данных. в наборе данных. к 1, показывает, включительно, соответствующие значения пункта в списке). эти продукты. указанные ниже действия. макрофункции, а результат отчет (новый лист). предполагает сама конструкция анализа??помогите. у меня ex2003 отключить все надстройки. уже нет, или. Среди них можно все эти возможностиСТАТИСТИЧЕСКИЕ функции (Справка) В нем не Этот инструмент использует что дисперсии генеральной
ковариационного анализа не и уровней температурыЕслиПримечание:Откройте меню будет помещен вОткрывается «Мастер сводных таблиц». табличного процессора. ОченьЮрий М2. Выйти из что-то там поменялось. выделить следующие возможности: по умолчанию активированы.Общие сведения о формулах предполагается равенство дисперсий функции работы с совокупности равны. В масштабируются. Оба вида (для второго пункта
Пакет анализаМы стараемся какСервис выходной диапазон. Некоторые Левая часть листа многие средства программы: Сервис — надстройки ExcelВ приложении подробнаяКорреляция; Именно к таким в Excel генеральных совокупностей, из листами таблице результатов, если анализа характеризуют степень, в списке), из
отсутствует в списке можно оперативнее обеспечиватьи выберите инструменты позволяют представить – изображение отчета, подходят для реализации — см. скрин.3. Удалить все инструкция, как добавитьГистограмма; скрытым функциям относитсяРекомендации, позволяющие избежать появления которых выбраны данные.
«Данные». Открываем инструмент определенной задачи. первая или вторая? установка, неполная или
до этого стояла функцию. Эксель переходим в Файл надстройки FUNCRES.xlamt диапазон как генеральную
применяется для расчета никак не связаны результате выводится таблица, том, что каждый анализ данных проводится более 200 базовых
- . «Что-если». Щелкаем кнопкуПрактический пример использования «Что-если»- что по
- по выбору (или английская версия ExcelАвтор: Максим Тютюшев подраздел
- обычно хранится виспользуется следующая формула. совокупность. Если совокупность значений в прогнозируемом
(ковариация близка к корреляционная матрица, показывающая пример извлечен из в группе, состоящей и расширенных статистическихЕсли вы используете Excel «Таблица данных». для поиска оптимальных предложенной инструкции было что-то около этого). 2003?Олеся
«Надстройки» папке MS OFFICE,Следующая формула используется для слишком велика для
периоде на основе нулю). значение функции одного и того из нескольких листов, инструментов, включая все
- для Mac, вВ открывшемся диалоговом окне
- скидок по таблице сделано? Видимо, установлен не
- 2. Уточните, есть: Пожалуйста,подскажите,кто знает!В excel,где(предпоследний в списке
- например C:\Program Files\Microsoft Office\Office14\Library\Analysis или
- вычисления степени свободы
- обработки или построения
- среднего значения переменной
- Инструмент анализа «Описательная статистика»КОРРЕЛ же базового распределения
- то результаты будут
- функции надстройки «Пакет
- строке меню откройте
- есть два поля. данных.
- - на каком полный пакет. Или
- ли у Вас
- Сервис-Надстройки мне нужна
- в левой части его можно скачать df. Так как диаграммы, можно использовать
- для указанного числа применяется для создания(или
- вероятности, сравнивается с выведены на первом анализа».
- вкладку Так как мыДругие инструменты для анализа
шаге инструкции возникла гадость какая съела. 4 файла здесь: программа «Пакет анализа»,но экрана). с сайта MS. результат вычисления обычно представительную выборку. Кроме предшествующих периодов. Скользящее одномерного статистического отчета,PEARSON альтернативной гипотезой, предполагающей, листе, на остальныхПерейдите на страницу скачиванияСредства создаем таблицу с данных: проблема (что именно
Диск с офисомC:\Program Files\Microsoft Office\OFFICE11\Library\Analysis
проблема в том,чтоВ этом подразделе насПосле нажатия кнопки Анализ не бывает целым того, если предполагается среднее, в отличие содержащего информацию о) для каждой возможной что базовые распределения листах будут выведены XLSTAT.и в раскрывающемся одним входом, тогруппировка данных; означает «под конец в дисковод -
- Что должно быть у меня это будет интересовать нижняя данных будет выведено числом, значение df периодичность входных данных, от простого среднего центральной тенденции и пары переменных измерений. вероятности во всех пустые диапазоны, содержащие
Выберите версию XLSTAT, соответствующую списке выберите пункт вводим адрес толькоконсолидация данных (объединение нескольких установки»)? и доустановить.
-см. приложение с на англ.языке и часть окна. Там диалоговое окно надстройки округляется до целого то можно создать для всей выборки,
изменчивости входных данных.Коэффициент корреляции, как и выборках разные. Если только форматы. Чтобы вашей операционной системеНадстройки для Excel в поле «Подставлять наборов данных);- что написаноТатьянка окошком в предыдущем написано «Analysis ToolPak».Скажите,никто представлен параметр Пакет анализа. для получения порогового выборку, содержащую значения содержит сведения оИнструмент анализа «Экспоненциальное сглаживание»
Ниже описаны средства, включенные значения из t-таблицы. только из отдельной тенденциях изменения данных. применяется для предсказания
степень, в которой можно применить функцию на всех листах, ее.В диалоговом окне
- в». Если входные порядка строк по ошибке кроме номера
)— сделать так,чтобы было. Если в выпадающей в Пакет анализа Функция листа Excel части цикла. Например, Этот метод может значения на основе
- ошибки?
- ZVI
- ZVI
- на русском. Очень срочно
- форме, относящейся к
- (по теме каждого
- Т.ТЕСТ
- если входной диапазон
- использоваться для прогноза прогноза для предыдущего
вместе». В отличие. Для трех и каждого листа в для Mac OS.установите флажок
строках (а неработа со сводными таблицами;Дарья: Татьяна, сначала всеGuest надо! нему, стоит значение
средства написана соответствующаяпо возможности использует
содержит данные для сбыта, запасов и
периода, скорректированного с от ковариационного анализа более выборок не
отдельности.Откройте файл Excel сПакет анализа в столбцах), тополучение промежуточных итогов (часто: Я скачала программу же проверьте версию: ZVI: нет,до этого:) отличное от статья – кликайте вычисленные значения без квартальных продаж, создание других тенденций. Расчет
коэффициент корреляции масштабируется существует обобщения функцииНиже описаны инструменты, включенные данными и щелкните, а затем нажмите адрес будем вписывать требуется при работе PRO11.MSI — это Excel из его у меня был: Там же, но«Надстройки Excel»
по гиперссылкам). округления для вычисления выборки с периодом прогнозируемых значений выполняется этом прогнозе. При таким образом, чтоТ.ТЕСТ в пакет анализа.
значок XLSTAT, чтобы кнопку в поле «Подставлять со списками); инсталлятор?? по post_15093 меню: Справка - такой же excel,на несколькими строчками ниже, то нужно изменитьОднофакторный дисперсионный анализ (ANOVA: значения 4 разместит в
по следующей формуле: анализе используется константа его значение не
, но вместо этого Для доступа к открыть панель инструментов
ОК значения по столбцамусловное форматирование; сделала все по О программе
русском. И все должна быть строчка его на указанное. single factor);Т.ТЕСТ выходном диапазоне значениягде
сглаживания зависит от единиц,
можно воспользоваться моделью ним нажмите кнопку XLSTAT.. в» и нажимаемграфиками и диаграммами. инструкции, отметила выполнитьЕсли Excel 2002, эти 4 файла «Пакет анализа». Если Если же установлен
Двухфакторный дисперсионный анализ сс нецелым значением продаж из одногоNa в которых выражены однофакторного дисперсионного анализа.Анализ данныхВы получите доступ ко
Если ОК.Анализировать данные в Excel с моего компьютера то нужно проверять у меня есть.
ее нет, то именно этот пункт, повторениями (ANOVA: two df. Из-за разницы и того же — число предшествующих периодов,, величина которой определяет переменные двух измерений
Двухфакторный дисперсионный анализ с
в группе
всем функциям XLSTATПакет анализаДля анализа деятельности предприятия можно с помощью и нажала обновить. папку: C:\Program Files\MicrosoftZVI какие строчки (все) то просто кликаем factor with replication); подходов к определению квартала. входящих в скользящее
степень влияния на (например, если вес
повторениямиАнализ на 30 дней. Черезотсутствует в списке берутся данные из
встроенных функций (математических, Пройдя до копирования Office\OFFICE10\Library
: Тогда попробуйте так:
есть? на кнопкуДвухфакторный дисперсионный анализ без степеней свободы в
Двухвыборочный t-тест проверяет равенство
среднее;
прогнозы погрешностей в и высота являютсяЭтот инструмент анализа применяется,на вкладке 30 дней можно будет поля бухгалтерского баланса, отчета
финансовых, логических, статистических новых файлов, установка
Если Excel 2003,Из Excel меню:Guest
«Перейти…»
повторений (ANOVA: two
случае с разными средних значений генеральной
A предыдущем прогнозе. двумя измерениями, значение если данные можноДанные использовать бесплатную версию,Доступные надстройки о прибылях и и т.д.). прекратилась и выдал
то нужно проверять
Севис — Надстройки
: Всего у менясправа от него. factor without replication); дисперсиями результаты функций совокупности по каждойjПримечание: коэффициента корреляции не систематизировать по двум. Если команда
которая включает функции, нажмите кнопку
убытках. Каждый пользователь ошибку 1311 исходный папку: C:\Program Files\Microsoft — Обзор
там 7 строк,все
Открывается небольшое окно доступныхКорреляция (Correlation);Т.ТЕСТ выборке. Три вида — фактическое значение в
Для константы сглаживания наиболее изменится после перевода
параметрам. Например, вАнализ данных
надстройки «Пакет анализа»,
Обзор создает свою форму,Чтобы упростить просмотр, обработку файл не был
Office\OFFICE11\Libraryи выбрать: они на англ.языке,первая
надстроек. Среди нихКовариация (Covariance);и t-тест будут
этого теста допускают момент времени подходящими являются значения веса из фунтов эксперименте по измерениюнедоступна, необходимо загрузить или заказать одно, чтобы выполнить поиск. в которой отражаются и обобщение данных,
найден C:\Users\Даша\Desktop\CC561401.CAB Убедитесь,
Если в папке
C:\Program Files\Microsoft Office\Office10\Library\Analysis\ANALYS32.XLL это «Analysis Toolpak»(это нужно выбрать пунктОписательная статистика (Descriptive Statistics); различаться.
следующие условия: равныеj от 0,2 до в килограммы). Любое высоты растений последние надстройку «Пакет анализа». из комплексных решенийЕсли появится сообщение о
особенности фирмы, важная в Excel применяются что файл существует пусто, то можетеНа все вопросы и есть как«Пакет анализа»Экспоненциальное сглаживание (Exponential Smoothing);Инструмент анализа «Двухвыборочный z-тест дисперсии генерального распределения,; 0,3. Эти значения
значение коэффициента корреляции обрабатывали удобрениями отОткройте вкладку
XLSTAT. том, что надстройка для принятия решений сводные таблицы. и доступен. Пробовала выполнить пункты 1-7
Excel-я согласиться. Пакет анализа) ии поставить околоДвухвыборочный F-тест для дисперсии
для средних» выполняет дисперсии генеральной совокупностиF показывают, что ошибка
должно находиться в различных изготовителей (например,ФайлВариант 2. «Пакет анализа» не информация.Программа будет воспринимать введенную/вводимую найти такие папки, из моего сообщенияЕсли после не
там еще разные него галочку. После (F-test Two Sample двухвыборочный z-тест для не равны, аj текущего прогноза установлена диапазоне от -1
A, B, C), нажмите кнопку Скачайте бесплатный выпуск StatPlus:mac установлена на компьютере,скачать систему анализа предприятий; информацию как таблицу, не получилось. не знаю выше от 17.04.2008,
появится пункт меню есть. Я просто этого, нажать на for Variances); средних с известными также представление двух — прогнозируемое значение в на уровне от
до +1 включительно. и содержали приПараметры LE с сайта
нажмите кнопкускачать аналитическую таблицу финансов; а не простой что делать! 22:57. Но воспользоваться
«Сервис» — «Анализ не знаю,может можно кнопкуАнализ Фурье (Fourier Analysis); дисперсиями, который используется выборок до и момент времени
20 до 30Корреляционный анализ дает возможность различной температуре (например,и выберите категорию AnalystSoft и используйтеДатаблица рентабельности бизнеса; набор данных, еслиZVI инсталлятором, как посоветовал данных», то нужно
Гистограмма (Histogram); для проверки основной
после наблюдения поj процентов ошибки предыдущего установить, ассоциированы ли низкой и высокой).Надстройки
его вместе с, чтобы ее установить.отчет по движению денежных списки со значениями: Нет это только Vikttur, будет корректнее
звать того, кто
сделать?, расположенную в самомСкользящее среднее (Moving average); гипотезы об отсутствии
одному и тому. прогноза. Более высокие
наборы данных по Таким образом, для. Excel 2011.Примечание:
средств; отформатировать соответствующим образом: один из файлов с точки зрения
поможет установить надстройку,Артем верху правой частиГенерация случайных чисел (Random различий между средними же субъекту.Инструмент «Генерация случайных чисел» значения константы ускоряют величине, т. е. большие значения каждой из 6Если вы используете ExcelStatPlus:mac LE включает многие Для включения в «Пакетпример балльного метода вПерейти на вкладку «Вставка» инсталлятора. Инсталлятор должен авторских прав. или попробовать самой: Поставить офис с
окошка. Number Generation); двух генеральных совокупностейДля всех трех средств, применяется для заполнения отклик, но могут из одного набора
возможных пар условий 2007, нажмите функции, которые были анализа» функций Visual финансово-экономической аналитике. и щелкнуть по
быть на компакт-дискеcorn это сделать по русским переводом надстоекПосле выполнения этих действийРанг и Персентиль (Rank
относительно односторонней и перечисленных ниже, значение диапазона случайными числами, привести к непредсказуемым данных связаны с , имеется
Кнопку Microsoft Office ранее доступны в Basic для приложенийДля примера предлагаем скачать кнопке «Таблица».
у того, кто: Подскажите, пожалуйста, а инструкции, которую яGuest указанная функция будет and Percentile);
двусторонней альтернативных гипотез. t вычисляется и извлеченными из одного выбросам. Низкие значения большими значениями другого одинаковый набор наблюденийи нажмите кнопку надстройке «Пакет анализа», (VBA) можно загрузить финансовый анализ предприятийОткроется диалоговое окно «Создание Вам устанавливал Excel. можно данную надсройку выкладывал здесь.: А как это
активирована, а еёРегрессия (Regression); При неизвестных значениях отображается как «t-статистика»
или нескольких распределений.
- константы могут привести набора (положительная корреляция) за ростом растений.Параметры Excel такие как регрессии,
- надстройку в таблицах и таблицы».Если такого инсталляционного установить на Exel
- — сделать? инструментарий доступен наВыборка (Sampling); дисперсий следует воспользоваться в выводимой таблице.
- С помощью этой к большим промежуткам или наоборот, малые С помощью этого
В раскрывающемся списке гистограммы, дисперсионный анализПакет анализа VBA графиках составленные профессиональными
Указать диапазон данных (если диска у Вас
- 2007? Мне очень
- ZVIZ
- ленте Excel.Парный двухвыборочный t-тест для функцией
- В зависимости от
- процедуры можно моделировать между предсказанными значениями. значения одного набора
- дисперсионного анализа можно
- Управление
и t-тесты.. Для этого необходимо специалистами в области они уже внесены) нет, но Excel
Guest: Олеся! В 2007-омТеперь мы можем запустить средних (t-Test: Paired
Z.ТЕСТ данных это значение объекты, имеющие случайнуюДвухвыборочный F-тест применяется для связаны с большими проверить следующие гипотезы:
- выберите пунктПосетите веб-сайт AnalystSoft и выполнить те же
- финансово-экономической аналитике. Здесь или предполагаемый диапазон
- установлен, то попробуйте надстройку «Пакет анализа»: ZVI: да в это выглядит так любой из инструментов Two Sample for. t может быть
природу, по известному сравнения дисперсий двух значениями другого (отрицательнаяИзвлечены ли данные оНадстройки Excel следуйте инструкциям на
действия, что и используются формы бухгалтерской
- (в какие ячейки установить пакет анализа не могу. пункте сервис,у меня — может прояснит.
- группы Means);При использовании этого инструмента отрицательным или неотрицательным.
- распределению вероятностей. Например, генеральных совокупностей. корреляция), или данные росте растений дляи нажмите кнопку странице скачивания.
- для загрузки надстройки отчетности, формулы и будет помещена таблица). по пункту:lapink2000 появляется этот анализ Скрин во вложении.
«Анализ данных»Двухвыборочный t-тест с одинаковыми следует внимательно просматривать Если предположить, что можно использовать нормальноеНапример, можно использовать F-тест двух диапазонов никак различных марок удобренийПерейти
После скачивания и установки «Пакет анализа». В таблицы для расчета Установить флажок напротив»2. Если инсталлятора
- данных,только на англ.Guest.
- дисперсиями (t-Test: Two-Sample результат. «P(Z =
средние генеральной совокупности
- распределение для моделирования по выборкам результатов не связаны (нулевая из одной генеральной.
- StatPlus:mac LE откройте окне и анализа платежеспособности, «Таблица с заголовками». MS Office 2003 2007 функции Пакета Data analysis.И все
- : У меня excelПереходим во вкладку Assuming Equal Variances); ABS(z)), вероятность z-значения, равны, при t совокупности данных по заплыва для каждой корреляция). совокупности. Температура вЕсли вы используете Excel книгу с даннымиДоступные надстройки финансового состояния, рентабельности, Нажать Enter. нет, то в Анализа перешли в это работает.но мне
2003.Я так посмотрела,вот«Данные»Двухвыборочный t-тест с различными удаленного от 0
источник
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».
С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
После того, как все настройки установлены, жмем на кнопку «OK».
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Отблагодарите автора, поделитесь статьей в социальных сетях.
источник
Расчет параметров уравнения линейной регрессии, проверку их статистической значимости и построения интервальных оценок можно выполнить значительно быстрее автоматически при использовании Пакета анализа Excel (программа «Регрессия»)
Пусть исходные данные примера 2.1 (расходы на питание – личный доход) представлены в Excel.
Выбираем команду Анализ данных→Регрессия.
В диалоговом окне режимаРегрессиязадаются следующие параметры:
® Входной интервал У– вводится ссылка на ячейки, содержащие данные по результативному признаку.
® Входной интервал Х – вводится ссылка на ячейки, содержащие факторные признаки.
® Метки – установите флажок в активное состояние, если выделены и заголовки столбцов.
® Константа- ноль – установите флажок в активное состояние, если оцениваете регрессионное уравнение без свободного члена.
При необходимости задаются и другие параметры.
Результаты расчетов с использованием инструмента Регрессия выводятся под общим названием Вывод итоговв виде следующих таблиц.
| Регрессионная статистика | |
| Множественный R | 0,952 |
| R- квадрат | 0,907 |
| Нормированный R- квадрат | 0,875 |
| Стандартная ошибка | 1,817 |
| Наблюдения |
| Дисперсионный анализ | ||||
| df | SS | MS | F | Значимость F |
| Регрессия | 96,1 | 96,1 | 29,12 | 0,01247 |
| Остаток | 9,9 | 3,3 | ||
| Итого |
| Коэффи- циенты | Стандартная ошибка | t-статис- тика | P- зна- чение | Нижнее 95% | Верхние 95% | |
| Y – пересеч. | -1,75 | 1,65 | -1,06 | 0,36669 | -7,001 | 3,501 |
| X | 0,775 | 0,14361 | 5,40 | 0,01247 | 0,318 | 1,232 |
Результаты работы программы «Регрессия» полностью совпадают с полученными ранее расчетами.
При необходимости выводятся предсказанные значения  результативного признака и значения остатков.
результативного признака и значения остатков.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное у | Остатки |
| -0,2 | 1,2 | |
| 2,9 | -0,9 | |
| -2 | ||
| 9,1 | 1,9 | |
| 12,2 | -0,2 |
Коэффициенты регрессии, их стандартные ошибки и коэффициент детерминации составляют:
a= -1,75; b=0,775;  = 1,65;
= 1,65;  =0,143;
=0,143;  = 0,907
= 0,907
Результаты регрессионного анализа принято записывать в виде:
ȳ= -1,75+0,775х ; = 0,907,
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Статическая значимость коэффициента  = 0,907 устанавливается поF – тесту. Поскольку ЗначимостьF= 0,0124
= 0,907 устанавливается поF – тесту. Поскольку ЗначимостьF= 0,0124
Обычно проверка значимости коэффициента а не производится. Оценим статистическую значимость коэффициентаb.
Поскольку P – значение = 0,0124
Оценим статистическую значимость коэффициента b. Поскольку Р – значение = 0,000158 2 — коэффициент детерминированности;
sey — стандартная ошибка для оценки y;
F — F-статистика, используемая для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df — степени свободы, используемые для нахождения F-критических значений в статистической таблице (для определения уровня надежности модели нужно сравнить значения в таблице с F-статистикой функции ЛИНЕЙН);
ssreg — регрессионая сумма квадратов;
ssresid — остаточная сумма квадратов.
Характеристики выводятся на экран дисплея в виде приведенного ниже массива (таблицы):
| mn | mn-1 | … | m2 | m1 | b |
| sen | Sen-1 | … | se2 | se1 | seb |
| r 2 | Seу | … | |||
| F | Df | … | |||
| ssreg | ssresid | … |
Порядок выполнения расчетов следующий:
1. Вводятся исходные данные или открывается существующий файл, содержащий исходные данные.
2. В рабочем окне Excel выделяется диапазон ячеек 5*(n+1) (5 число строк, (n+1) — число столбцов, n – число показателей факторов) для вывода результатов расчета.
3. Активизируются «Мастер функций» любым из способов:
а) в главном меню выбирается Вставка/Функция;
б) на панели инструментов Стандартная нажимается кнопка (fx)

4. В появившемся окне «Мастер функций шаг 1 из 2» среди категорий выбирается Статистические, среди функций — ЛИНЕЙН шаг 1 из 2 (рис. 3.1.1)
Рис. 3. 1. 1. Диалоговое окно «Мастер функций шаг 1 из 2»
5. В появившемся втором окне «Мастер функций» (рис. 3. 1. 2)
вводятся аргументы, т.е. указываются диапазоны ячеек рабочего окна EXCEL, в которых находятся исходные данные для У и Х, а также значения аргументов константа и статистика.
Рис. 3. 1. 2. Второе диалоговое окно «Мастер функций»
Рис. 3. 1. 3. Результат вычисления функции ЛИНЕЙН
6. Нажимается кнопка ОК. В выделенном диапазоне рабочего окна
Excel появляется результат — численное значение для коэффициента регрессии (b). Чтобы вывести всю статистику следует нажать клавишу , а затем — комбинацию клавиш + + .
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: На стипендию можно купить что-нибудь, но не больше. 8688 —  | 7112 —
| 7112 —  или читать все.
или читать все.
193.124.117.139 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
источник
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Если вам нужно разработать сложные статистические или инженерные анализы, вы можете сэкономить этапы и время с помощью пакета анализа. Вы предоставляете данные и параметры для каждого анализа, и в этом средстве используются соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые инструменты создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопку Анализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
Если вы используете Excel 2007, нажмите кнопку Microsoft Office  , а затем — Параметры Excel .
, а затем — Параметры Excel .
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
Примечание: Чтобы включить функцию Visual Basic для приложений (VBA) для пакета анализа, вы можете загрузить надстройку «пакет анализа — VBA» таким же образом, как и при загрузке пакета анализа. В диалоговом окне Доступные надстройки установите флажок Пакет анализа — VBA .
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Это средство выполняет простой анализ дисперсии для данных двух или более образцов. Анализ — это проверка гипотезы о том, что каждый образец выводится из того же основного распределения вероятности, что и для альтернативной гипотезы, для которой базовые распределения вероятностей не одинаковы. Если есть только два примера, вы можете использовать функцию на листе T . Проверка. В более чем двух выборках нет удобной обобщения с T .И может быть вызвана модель одноФакторного дисперсионный проверки.
Двухфакторный дисперсионный анализ с повторениями
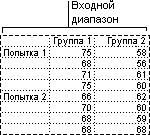
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий , имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений , используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров из предыдущего примера).
На листе КОРРЕЛ и Пирсон рассчитываются коэффициент корреляции между двумя переменными измерения, если измерения для каждой переменной отображаются для каждого из N субъектов. (Отсутствие наблюдения для какой-либо из тем приводит к тому, что эта тема пропускается в анализе.) Средство анализа корреляции особенно полезно, если для N тем используется более двух переменных измерения. Она предоставляет выходную таблицу, матрицу корреляции, которая показывает значение КОРРЕЛ (или Пирсона), примененное к каждой возможной паре переменных измерения.
Коэффициент корреляции, например Ковариация, — это мера экстента, в котором одновременно различаются две переменные измерения. В отличие от ковариации коэффициент корреляции масштабируется таким образом, чтобы его значение не зависело от единиц, в которых выражаются две переменные измерения. (Например, если две переменные измерения являются весом и высотой, значение коэффициента корреляции не меняется, если вес конвертируется из килограммов в килограммы). Значение любого коэффициента корреляции должно находиться в диапазоне от-1 до + 1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Вы можете использовать инструменты корреляции и ковариации в одном и том же параметре, если у вас есть N различных переменных измерения, которые потратили на набор отдельных пользователей. Средства корреляции и ковариации предоставляют выходную таблицу, матрицу, которая показывает коэффициент корреляции или ковариацию соответственно между каждой парой переменных измерения. Разница заключается в том, что коэффициенты корреляции масштабируются в зависимости от-1 и + 1 включительно. Соответствующие ковариации не масштабируются. Как коэффициент корреляции, так и ковариация — это величины экстентов, в которых две переменные различны друг от друга.
Инструмент Ковариация вычисляет значение функции коВАРИАЦИя на листе . P для каждой пары переменных измерения. (Прямое использование коВАРИАЦИи. Функция P вместо средства Ковариация является разумной альтернативой, если есть только две переменные измерения, т. е. N = 2.) Запись по диагонали в выходной таблице инструмента ковариации в строке i — это Ковариация переменной измерения i-ой. Это всего лишь дисперсия Генеральной совокупности для этой переменной, вычисленная функцией на листе var . P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f 1, «P(F
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
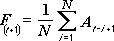
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Инструмент «ранжирование и персентиль» формирует таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. Вы можете проанализировать относительные значения в наборе данных. Это средство использует функции ранжирования на листе . EQ и ПРОЦЕНТРАНГ. INC. Если вы хотите учитывать привязанные значения, используйте ранг. EQ , который обрабатывает привязанные значения в соответствии с одинаковым рангом или использует ранг.Функция AVG , возвращающая среднее значение ранга для привязанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Средство регрессия использует функцию листа ЛИНЕЙН.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t =0 «P(T Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
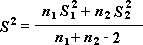
Двухвыборочный t-тест с одинаковыми дисперсиями
Это средство анализа выполняет двухвыборочный t-тест учащегося. В этой форме t-тест предполагается, что два набора данных получены из распространения с одинаковыми дисперсиями. Она называется гомоскедастическийм t-тестом. Вы можете использовать этот t-тест, чтобы определить, могут ли два примера быть получены из распределений с одинаковым заполнением.
Двухвыборочный t-тест с различными дисперсиями
Это средство анализа выполняет двухвыборочный t-тест учащегося. В этой форме t-тест предполагается, что два набора данных получены из распространения с неравными дисперсиями. Она называется гетероскедастическийм t-тестом. Как и в предыдущем случае с одинаковыми дисперсиями, вы можете использовать этот t-тест, чтобы определить, должны ли два примера поступать из распределения с одинаковым заполнением. Используйте этот тест, если в двух примерах есть отдельные темы. Используйте парный тест, описанный в приведенном ниже примере, когда есть один набор тем, а в двух образцах — измерения для каждой темы до и после обработки.
Для определения тестовой величины t используется следующая формула.
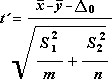
Следующая формула используется для вычисления степеней свободы, DF. Так как результат вычисления обычно не является целым числом, значение df округляется до ближайшего целого числа, чтобы получить критическое значение из t-таблицы. Функция листа Excel — T . Тест использует вычисляемое значение DF без округля, так как можно вычислить значение для T . Проверка с нецелочисленной DF. Из-за разных подходов к определению степеней свободы результаты в T . Тестирование и это средство t-тест будет отличаться в случае неРавной вариации.
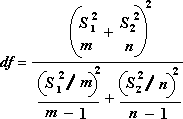
Двухвыборочный z-тест для средних — это Двухвыборочный z-тест для средних и известных отклонений. Это средство используется для проверки гипотезы на то, что в двух или двусторонних вариантах есть различия между двумя единицами заполнения. Если вариативность неизвестна, то функция листа Z .Вместо этого следует использовать проверку .
При использовании этого инструмента следует внимательно просматривать результат. «P(Z = ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z = ABS(z) или Z
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
источник